Unlocking Insights from Twitter Data with Neo4j: A Hands-On Tutorial
Written by Michalis Charatzoglou, Maria Liatsikou & Sofia Vei — April 2023

Social media platforms generate massive amounts of data every day, providing an opportunity to gain valuable insights into trends, opinions, and behaviours. Twitter, one of the most popular social media platforms, is particularly rich in data that can be analysed to gain insights into user behaviour and sentiment. With over 330 million monthly active users, it generates a massive amount of data every day, including tweets, retweets, hashtags and URLs, which can be analysed to identify trends, opinions, and behaviours. Analysing Twitter data can be challenging due to its unstructured and constantly evolving nature. This is where graph databases like Neo4j come in. In this tutorial, we will explore how to use the Neo4j graph database and Python to analyse Twitter data. We will cover topics such as setting up Neo4j, importing Twitter data into Neo4j, and running queries to answer a set of predefined questions. We will also showcase how to use advanced graph algorithms such as Pagerank and Louvain. By the end of this tutorial, you will have the knowledge and tools to analyse Twitter data and gain valuable insights into user behaviour and sentiment. Let’s get started!
The first step in this process is to extract the Twitter API data from the MongoDB database using py2mongo, which is a Python library that provides a simple interface for interacting with MongoDB. Once the data has been extracted, we’ll need to transform it into a format that can be used by Neo4j. Along with the -fairly detailed- description of this step you will be gaining a handful insight on the way we are using our data:
To achieve this, we’ll create a set of methods that will generate lists of dictionaries representing all of the necessary nodes and relationships for the Neo4j database. These methods will be designed to be easily integrated into the overall process, allowing for plug-and-play functionality.
The method for generating nodes will need to extract all of the relevant data from the MongoDB database and package it into a dictionary that can be easily used by Neo4j. This will include information such as user, tweets, hashtags and urls.
Similarly, the method for generating relationships will need to identify the relevant connections between nodes in the data and package them into a dictionary format.
Overall, by creating these methods and using py2mongo to extract the data from the MongoDB database, we can simplify the process of making Twitter API data compatible with a Neo4j database. With this approach, we can generate all necessary nodes and relationships and create a plug-and-play solution for anyone who needs to extract and use Twitter data in a Neo4j database. For illustrative purposes we include the code that generates the list of tweet objects and also the code that generates the list of dictionaries representing users who tweeted at least one tweet, but you can find the full code for this part here.
set_mongo_connection: This function creates a connection to a MongoDB database using the pymongo.MongoClient class. It authenticates with the database, if necessary, and returns a MongoClient object that can be used to interact with the database. This helps keep the code modular and provides a single point of entry for connecting to the database.
Tweet nodes
get_node_tweets: This function takes a MongoDB collection as input and returns a list of tweet objects, containing the tweet ID, author ID, creation date, retweet count, and list of referenced tweets. If the tweet object also contains a list of referenced tweets, this list (containing the type and tweet_id attributes) is extracted and added to the output tweet object. If no referenced tweets are found, the function adds a dummy object with the type and tweet_id attributes set to None.
User nodes
get_node_users: This function retrieves distinct users from a collection based on two criteria: includes.users field and includes.tweets.0.entities.mentions field. It extracts user information, stores it in a list of dictionaries, and removes duplicates. The list is sorted by tweet creation date, and each user object contains ID, number of followers, username, and creation date.
Hashtag nodes
get_node_hashtags: The function returns a list of unique hashtags found in tweets stored in the collection. It finds all documents with a “hashtags” field, iterates over each hashtag in each document, adds the lowercase version to the set, and finally returns the set as a list of unique hashtags.
URL nodes
get_node_urls: The function extracts all the unique URLs from a MongoDB collection of tweets. It queries the collection for documents with URLs in the first tweet’s entities.urls field, and then adds each unique URL to a set. The set is converted to a list, and the function returns the list of unique URLs.
TWEETED relationship
get_relationship_tweeted: This function returns a list of dictionaries representing users who tweeted at least one tweet. The function queries the collection for tweets that are not replies, quotes, or retweets. For each tweet, it retrieves the user ID, tweet ID, and creation date. If the user ID is not already in the list, a new dictionary with the user ID and empty lists of tweeted tweet IDs and creation dates is created. The tweet ID and creation date are then appended to the respective lists in the dictionary. Finally, a list of the user dictionaries is returned.
RETWEETED relationship
get_relationship_retweeted: The function retrieves a list of dictionaries representing users who retweeted at least one tweet. It queries the MongoDB collection for documents where the tweets field exists and extracts the user ID, tweet ID, and creation date of the tweet. It then checks if the tweet is a retweet by looking at the type field of the referenced_tweets list. If it is a retweet, it adds the user ID, retweeted tweet ID, and creation date to a dictionary for that user. Finally, it returns a list of the user dictionaries containing their information.
QUOTED relationship
get_relationship_quoted: The function returns a list of dictionaries with user IDs, a list of quoted tweet IDs, and their creation dates. It looks for documents where the includes.tweets.0.referenced_tweets field exists, which means the tweet is a reply, quote, or retweet. Then it retrieves the user ID, tweet ID, and creation date. If the tweet is a quote, it checks if the user ID exists in the user_quoted_tweet dictionary, initialises a new dictionary if not, and appends the quoted tweet ID and creation date to respective lists in the dictionary. Finally, the function returns a list of the values of the user_quoted_tweet dictionary.
REPLIED_TO relationship
get_relationship_replied_to: This function returns a list of dictionaries representing users who replied to at least one tweet. It starts by querying the collection for documents where the tweet is a reply. For each document, the function retrieves the user ID, tweet ID, and creation date of the tweet. If the user ID does not exist in the user_replied_to_tweet dictionary, a new dictionary is initialised with the user ID, an empty list of replied tweet IDs, and an empty list of creation dates. The function then appends the replied tweet ID and creation date to the respective lists in the dictionary. Finally, the function returns a list of the values of the user_replied_to_tweet dictionary, which are the dictionaries containing the user’s information.
HAS_HASHTAG relationship
get_relationship_has_hashtag: This function finds tweets that have at least one hashtag in their “entities” field and returns a list of dictionaries representing each unique tweet. Each dictionary contains the tweet ID and a list of unique hashtags associated with the tweet. The function creates a set to store the unique hashtags, extracts the hashtags from the “entities.hashtags” field, and converts them to lowercase to ensure case-insensitivity. The function then creates a dictionary for each unique tweet and adds it to the output list. This function helps analyse the relationship between tweets and hashtags.
HAS_URL relationship
get_relationship_has_url: This function finds tweets with URLs in a MongoDB collection and returns a list of dictionaries containing the tweet ID, URLs, and associated user ID. It searches for documents with includes.tweets.0.entities.urls field and loops through each document. For each tweet, it checks if the ID is unique, extracts the URLs, removes duplicates, and creates a dictionary with the tweet ID, URLs, and user ID. Finally, it returns the list of dictionaries.
USED_HASHTAG relationship
get_relationship_used_hashtag: This function takes a MongoDB collection as input and returns a list of dictionaries representing users and the unique hashtags they used in their tweets. It retrieves documents with at least one tweet that has at least one hashtag and loops through each document to extract the user ID and hashtags used in each tweet. The function then creates a dictionary for each user containing their ID and a set to store their unique hashtags. For each hashtag in the tweet, it adds it to the set. Finally, the function converts the dictionary to a list and returns it. This function is useful for analysing how users engage with specific topics or hashtags.
USED_URL relationship
get_relationship_used_urls: The function takes a MongoDB collection of tweets and returns a list of dictionaries representing the relationship between Twitter users and the URLs they’ve used in their tweets. It finds all documents that have at least one tweet with URLs and loops through each document to extract the first tweet and user ID. If the user ID isn’t in the dictionary, it initialises a new entry for that user with an empty set of URLs. For each URL in the tweet’s “entities” field, it adds it to the user’s set of URLs and converts the set to a list. Finally, the dictionary is converted to a list of dictionaries and returned as the output.
MENTIONED relationship
get_relationship_mentioned: The function extracts information from a MongoDB collection of tweets and returns a list of dictionaries that represent the relationship between Twitter users who have mentioned each other in their tweets. The function loops through each tweet to identify the users who have been mentioned and increments the count of mentions for each mentioned user. It then converts the dictionary of relationships to a list of dictionaries and returns it as output.
We’ve set up our data and now we are ready to load it in Neo4j to start quering!
First, follow these simple instructions to set up your environment:
- Go to the Neo4j download page: https://neo4j.com/download/
- Choose the appropriate download option for your operating system.
- Follow the installation instructions for your operating system.
- Once installed, open the Neo4j browser by navigating to http://localhost:7474/ in your web browser.
- Log in with the default credentials: username “neo4j” and password “neo4j”.
- You will be prompted to change your password, follow the instructions to set a new password.
- Once logged in, you can start using Neo4j to create and manage your graph database.
Congratulations, you have successfully installed Neo4j! Now you can move on to the next step of the tutorial, which is populating the Neo4j graph model with the Twitter data.
Firstly, you should create a new project and add a local database in Neo4j, giving a name and a password. This is where your data will be uploaded, so keep in mind that you will need these credentials right afterwards.
To connect through Python to Neo4j, you can very easily add your credentials as prompted:
As a first step we populate the database with the graph nodes. We have nodes with four different labels: Tweets, Hashtags, URL and Users. After creating the corresponding lists, as described previously, we create the nodes along with their labels and attributes in Neo4j. For example in the snippet below we can see how the Tweet nodes are created.
Afterwards, we create the necessary relationships between nodes. All the relationships we need are described previously. We indicatively showcase how we create the TWEETED relationship. As shown in the snippet below, we firstly create the corresponding list, by retrieving the data from the MongoDB collection, and then for every user we merge her node based on user id and we also merge the Tweet nodes, that correspond to her, based on the tweet id. Finally we create the TWEETED relationship by also adding the property which refers to the creation date of the specific tweet. We follow the same steps for the rest of the seven relationships we have already described.
We go on by listing our queries and their solutions one by one, for convenience. For that, we are using py2neo to fulfil our Cypher queries in Python.
1. Get the total number of retweets.
The total number of retweets is: 24252We also calculated -behind the scenes- the total number of tweets and quotes, and comparatively we see that the retweets (24252) take up the largest part of our data.
2. Get the 20 most popular hashtags (case insensitive) in descending order.
The 20 most popular hashtags in descending order are:
popular_hashtags frequency
0 womenintech 4506
1 womenempowerment 3736
2 genderequality 3205
3 100daysofcode 1018
4 womenwhocode 990
5 women 931
6 ai 877
7 coding 855
8 violence 815
9 datascience 745
10 womeninstem 717
11 python 690
12 womeninscience 689
13 tech 684
14 programming 611
15 javascript 562
16 womenentrepreneurs 523
17 bigdata 518
18 technology 503
19 blacktechtwitter 477Here we also print the corresponding frequencies for demonstration purposes. We notice that with great difference, the three most popular hashtags are #womenintech, #womenempowerment and #genderequality. Interestingly, all three hashtags share the idea of promoting gender equality and women’s empowerment. Overall, combining not only the idea behind the first three but all the popular hashtags that were produced, we conclude that the powerful symbol of the ongoing struggle for gender equality in technology is very strong behind our data.
3. Get the total number of URLs (unique).
The total number of urls is: 9136Combining this number with the number of retweets from query 1, we get that the users tend to share external content through retweets but especially combining it with the much lower number of tweets that we calculated off the record, it could suggest that users are relying heavily on external sources to inform their conversations on Twitter. This may indicate that the platform is highly used for content distribution.
4. Get the 20 users with the most followers in descending order.
The 20 users with most followers in descending order are:
username followers
0 elonmusk 128282742
1 narendramodi 86387842
2 CNN 61110504
3 MileyCyrus 46930879
4 POTUS 29400524
5 FoxNews 23704890
6 Forbes 18710133
7 ICC 18401325
8 ndtv 17700505
9 UN 16213190
10 smritiirani 12724316
11 harbhajan_singh 11848884
12 PiyushGoyal 11685985
13 TimesNow 10325121
14 binance 10164724
15 TheDailyShow 9499257
16 ANI 7554914
17 snooki 5943793
18 Mike_Pence 5823821
19 Cobratate 4996182Well, obviously! Elon Musk is the highest in popularity as far as followers is concerned, with second competitor Narendra Modi, by getting the second position with a considerable difference, though. Again, we also printed the corresponding number of followers, just to check.
5. Get the hour with the most tweets and retweets.
The hour with the most tweets and retweets is the 15 thThe hour with the most tweets and retweets turns out to be 3pm. Interestingly enough, many social media marketing companies like Metricool and G2 suggest that brands should post mostly on this time to get more visibility and interactions!
6. Get the users, in descending order, that have been mentioned the most.
The 20 users, in descending order, that have been mentioned the most are:
username number_of_mentions
0 Microsoft 6132
1 anthonyjdella 6124
2 Equal_Fights 988
3 FightHaven 745
4 see_fullen 737
5 GirlsWhoCode 423
6 ToofaniBaba1 307
7 NCMIndiaa 246
8 Khulood_Almani 233
9 NorthernComd_IA 197
10 WomensVoicesNow 177
11 HarishKhuranna 157
12 BJP4Delhi 157
13 Virend_Sachdeva 157
14 jindadilkashmir 156
15 sanjeevchadha8 156
16 TMGAwards 132
17 UN_Women 125
18 PointerSchool 122
19 emily_gunton 121Judging from the number of mentions which we also printed, the two most mentioned users here sharing the greatest number are Microsoft and anthonyjdella. There is not much more to comment on here, until we get to our 8th query and do the right comparison.
7. Get the top 20 tweets that have been retweeted the most and the persons that posted them.
The top 20 tweets that have been retweeted the most and the persons that posted them are:
tweet_id author_id retweets
0 1617735335408017410 1162333473966891008 23351
1 1617723820604854272 1499144181822136320 23351
2 1614904562577715202 736244975944400896 21311
3 1616739692153802753 1578001920169750533 21311
4 1615338234250407936 1477971375100887042 21311
5 1615254039788400642 1571833730783940609 21311
6 1617351171341180928 3271065654 21311
7 1616741044154175491 1120982776843399169 21311
8 1616748922441199621 1488570069689204736 21311
9 1616812458999681025 3093825314 21311
10 1615752926869192711 1542755697087102976 21311
11 1617535902116642818 1061286182313635842 21311
12 1617895018127314944 1587502588957806599 21311
13 1615988984060207110 1605845393081712640 21311
14 1614904554247815170 736244975944400896 11731
15 1617351148654178305 3271065654 11731
16 1615254025657815041 1571833730783940609 11731
17 1617351191033413634 3271065654 11574
18 1617750374051622913 720112912212340736 11574
19 1615254048357388288 1571833730783940609 11574Here, printing additionally the number of retweets for each tweet, we can see that out of the 20 results in the output, many tweets share the same number or retweets. This is just a coincidence!
8. Get the most “important” user in the dataset using Pagerank algorithm in the MENTIONED network.
The 10 highest PageRank values for the 'Mentioned' network are: username score
0 Microsoft 1350.284733
1 anthonyjdella 1348.455038
2 Equal_Fights 435.071162
3 FightHaven 165.819832
4 see_fullen 163.434105
5 ToofaniBaba1 126.009123
6 GirlsWhoCode 108.295472
7 _EllaBot 108.164522
8 PythonRoboto 95.285458
9 NCMIndiaa 86.950705
The most important user according to the highest PageRank value is: MicrosoftWe also print the 10 highest Pagerank scores for the MENTIONED network for comparative purposes. PageRank outputed Microsoft as the most important user. It is quite reasonable, since Pagerank is a widely used algorithm that calculates the importance of a node in a network based on its connections to other nodes. In the context of a Twitter mention network, Pagerank can help identify users who are influential in terms of being mentioned or retweeted frequently by other users, and Microsoft is definitely exactly this. As a second notice, Microsoft and anthonyjdella share the highest scores with a huge difference. Finally, combining the PageRank scores with the most mentioned users in query 6, we notice that the five first users of both queries are the same, sharing even the same order, concluding to concrete high mention numbers for the users.
9. Get the users that post tweets with hashtags most similar to those used by the most important user.
Τhe 20 users who used most similar hashtags to the 6th important user are: ('sanyaolu', 'saviour_era', 'serenity0312_', 'shiva649531', 'skverma_110', 'talokbhansingh', 'team668866', 'unearthing_29', 'utterlypositive', 'vickypandey1571', 'vikramsaini32', 'vskumarcs', 'yamane_patricia', 'Arbazkhan98786', 'Prvesh17833226', 'Sajeed63814075', 'elisa_kiswa', 'abdulazizbhat83', 'meherabid86', 'quamahbeer91')For this query, as one can notice, we chose the 6th more important user as the first five have not used any hashtags. To calculate the results for the query we used Jaccard similarity. The 20 users with the most similar hashtags to this user are as presented in the results.
10. Get the user communities that have been created based on the users’ interactions and visualise them (Louvain algorithm).
username communityId
0 Sukhmanjeetkau2 0
1 LauraDoodlesToo 825
2 AnastasiaNFTart 825
3 esquivel_gifted 23977
4 DevonGarritt 23977
... ...
25630 OscarLegariaMMA 11458
25631 Ca1d3_ 11458
25632 Irit_Kogan 11458
25633 HassanMizukage 11458
25634 Suuuuuuuuuuuux 21440
[25635 rows x 2 columns]The query results in getting the community that each user belongs to in the MENTIONED network, according to the Louvain algorithm.
A little extra:
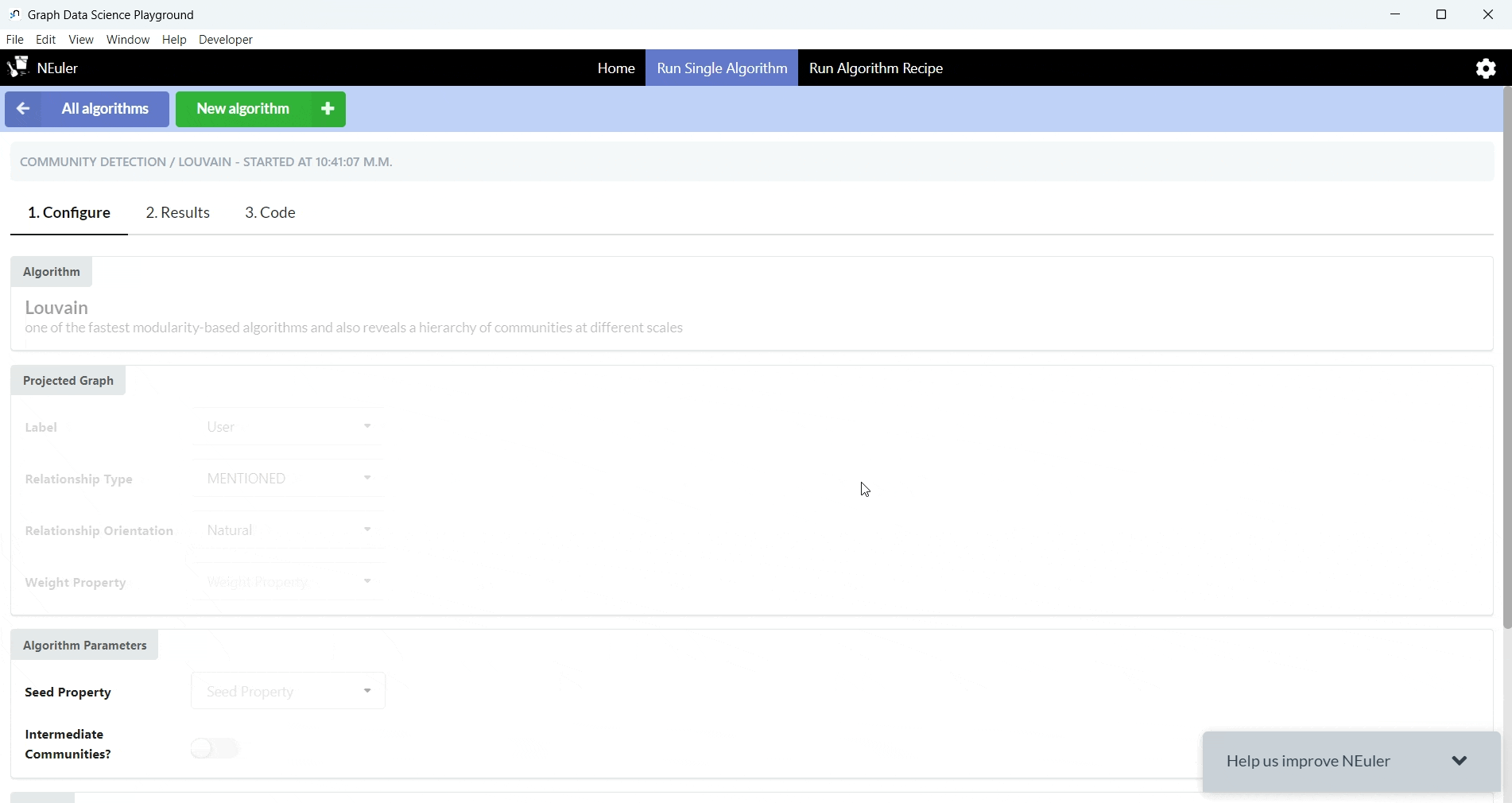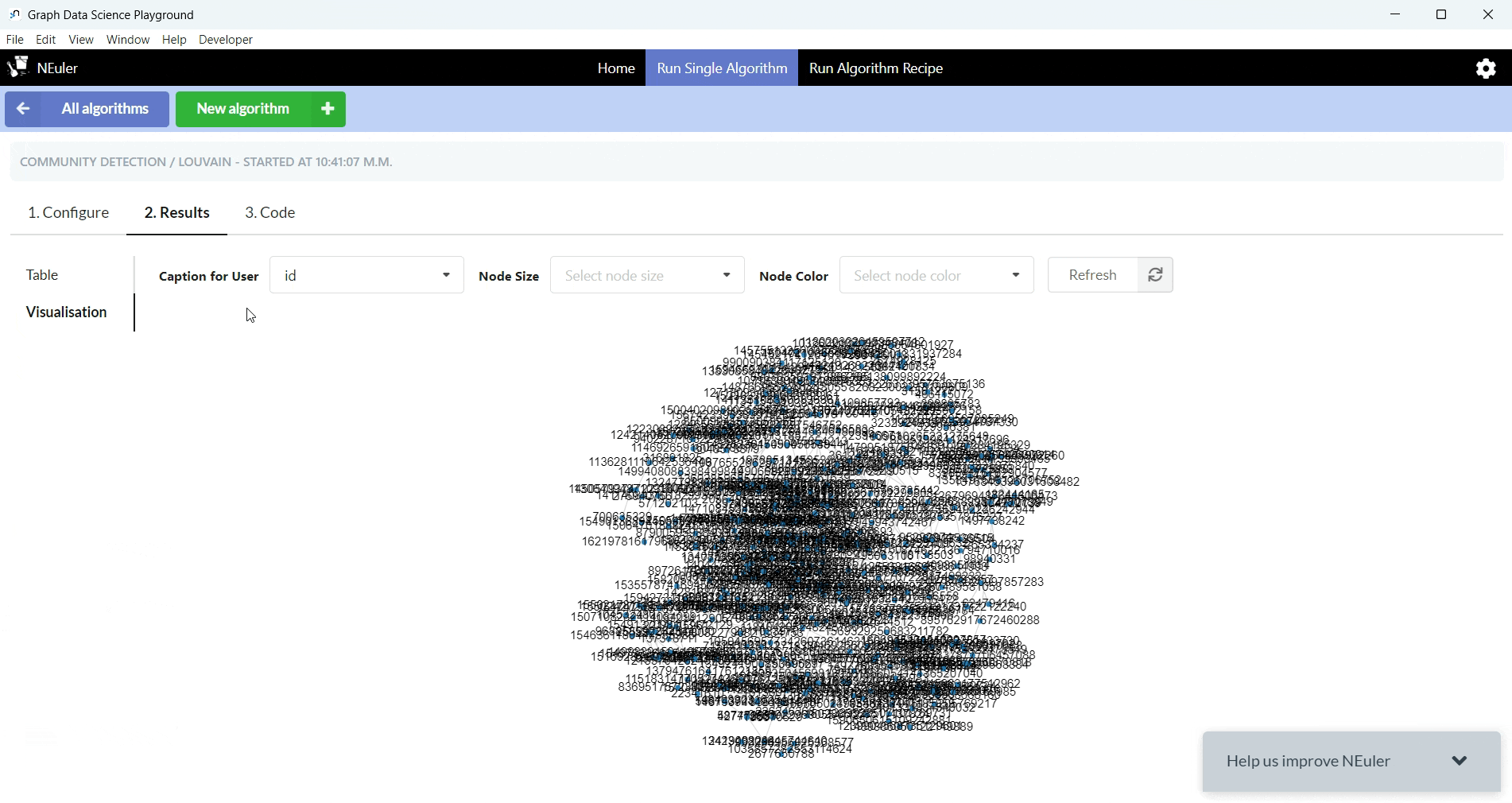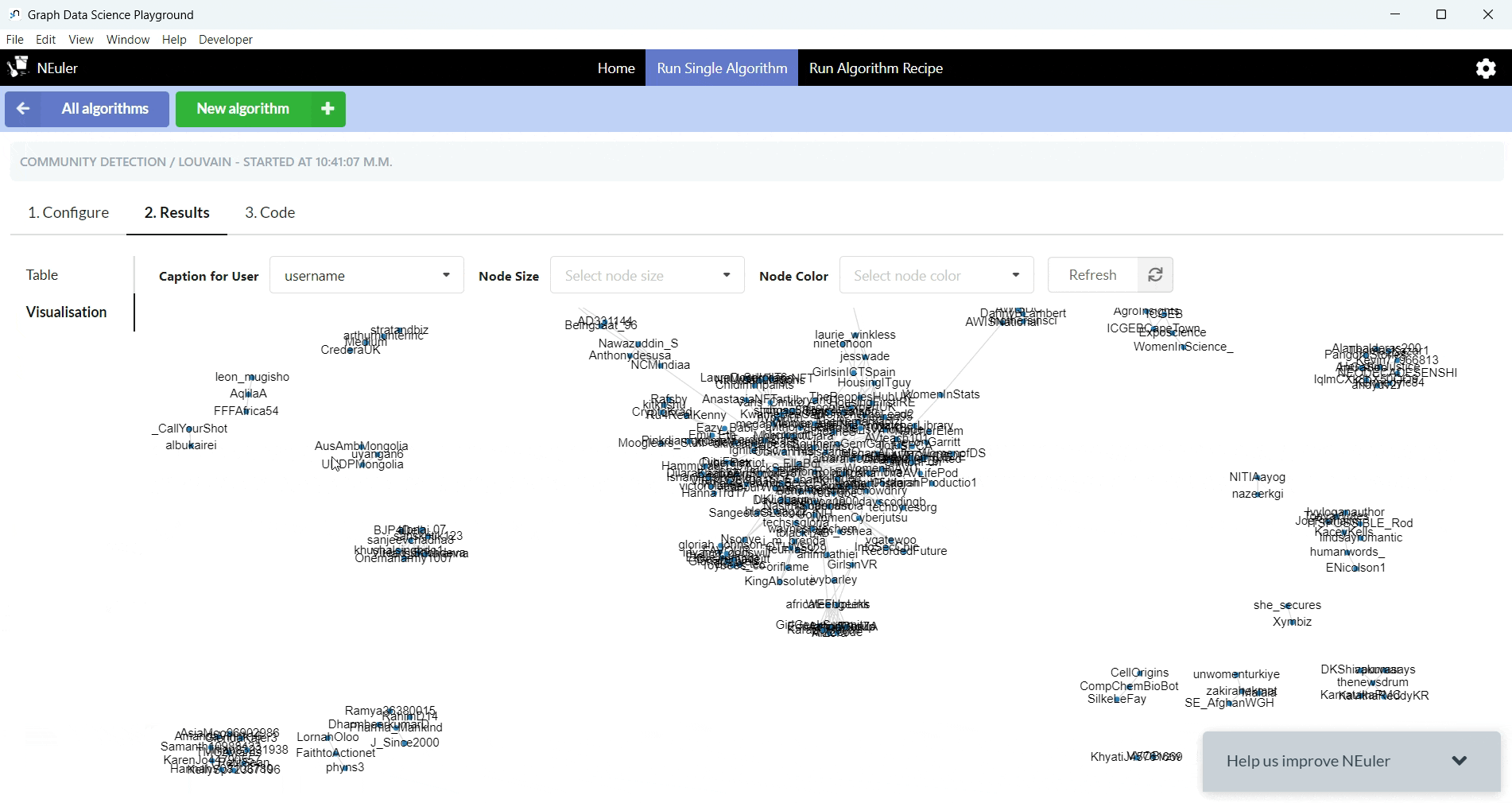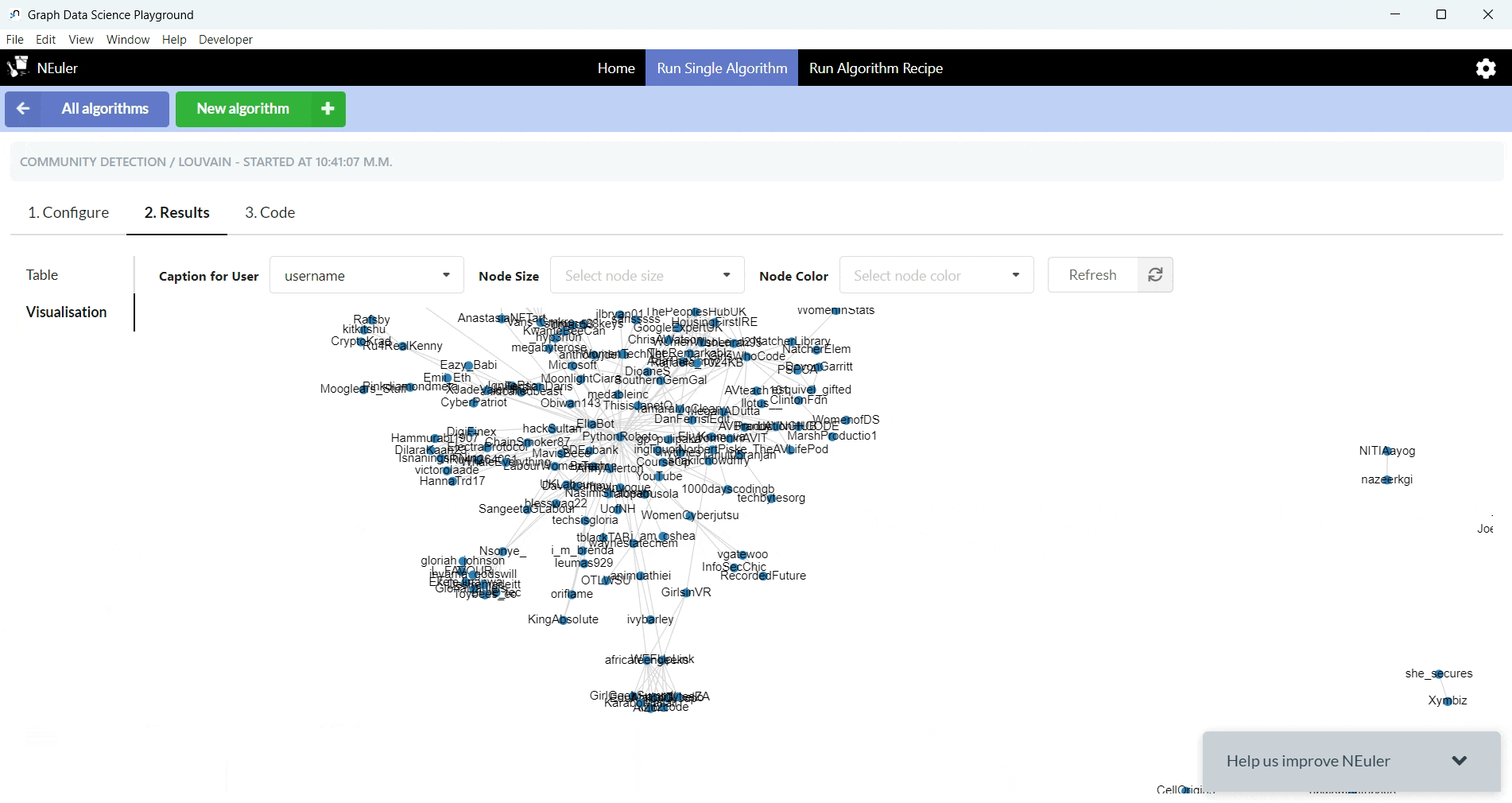
For this query, we are very excited to also introduce NEuler: the Graph Data Science Playground, an app which is a no-code way that helps you with the Graph Data Science library. NEuler can help you do three things: configure algorithms, explore the results and see the code. There are many other tools which you can use to visualise your results, but this way will help you accomplish everything you need through Neo4j.
You can easily download Graph Data Science Playground through your Graph Apps Gallery in Neo4j Desktop. Note that you should also download the corresponding plugin to your Neo4j version.
Connect to the server and select the database that you want to work on.
Once you’re in, you can choose from a great variety of algorithms, labels, relationship types etc, so that you can create the model you wish.
You will get your results in a table format as long as the visualisation where you will be able to represent the nodes as you want.
Additionally, you will get the corresponding code in Cypher, which you can send to your Neo4j Browser where you can run it.
By default, your visualisation will produce a graph with up to 300 nodes. To change that, you can run the following piece of code in Cypher, adjusting the number as you wish:
Afterwards you can extract your visualisation as an image, as we did.
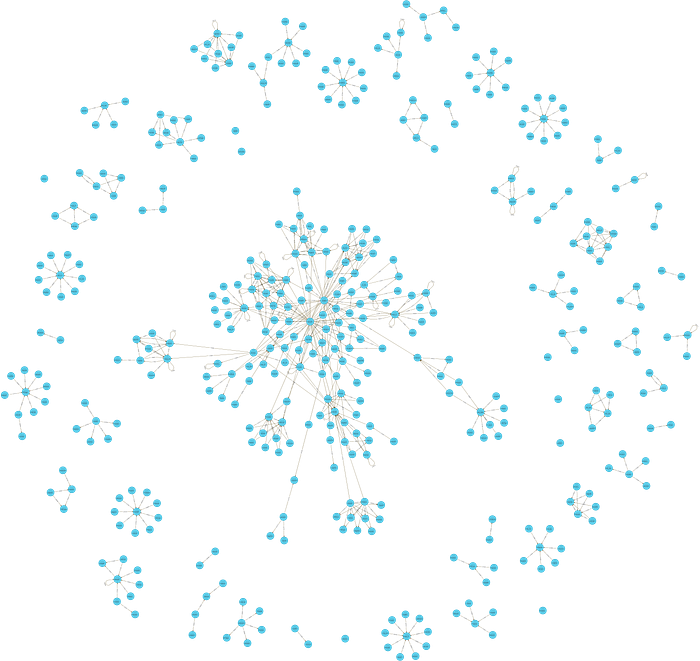
This is an easy way to visualise your algorithm’s results. Of course, there are other, more fancy ways, but we will get to that later!
11. Get the top 10 most active users along with the number of posts they have made.
The top 10 most active users along with the number of posts they have made:
username number_of_posts
0 bcsn_official 262
1 CourseOp 116
2 Lemetellusthg 96
3 Global1Event 79
4 Financedata1 78
5 Mahsamoulavi 78
6 DipsLab3 57
7 TrueMisnomers 57
8 WeSabio 55
9 KerenaNicole 54Here, we decided to combine the most active users with the number of posts they created. Interestingly enough, Elon Musk and Microsoft were not in the list this time.
12. Get the volumes of each type of tweets (where None is a tweet).
The volumes of each type of tweets are:
type volume
0 retweeted 24252
1 None 7133
2 quoted 743
3 replied_to 954For the last query, we decided to check the types of all our tweets. In the first query we calculated the retweets, but it was interesting to see the distribution for all the types in our data. “None” here corresponds to the initial tweets created, which is clearly a smaller number to the retweeted ones.
Bonus part:
In case you’re interested in a more fancy visualisation, we are suggesting GraphXR, another app in Neo4j Desktop, which you can download exactly as NEuler.
Once you open GraphXR, your database will be already in there, since it is connected to your Neo4j instance.
You can visualise any nodes or relationships you wish, even the whole dataset with all the relationships, but we decided to run Label Propagation, another community detection algorithm, on user nodes with the MENTIONED relationship — as we previously did with Louvain.
To run the algorithm as we did, firstly choose your category and relationship -we chose users and MENTIONED, respectively- from the Project tab in GraphXR.
Then, in the Algorithm section choose Label Propagation and filter the nodes with the labelPropagationId.
Voilà!
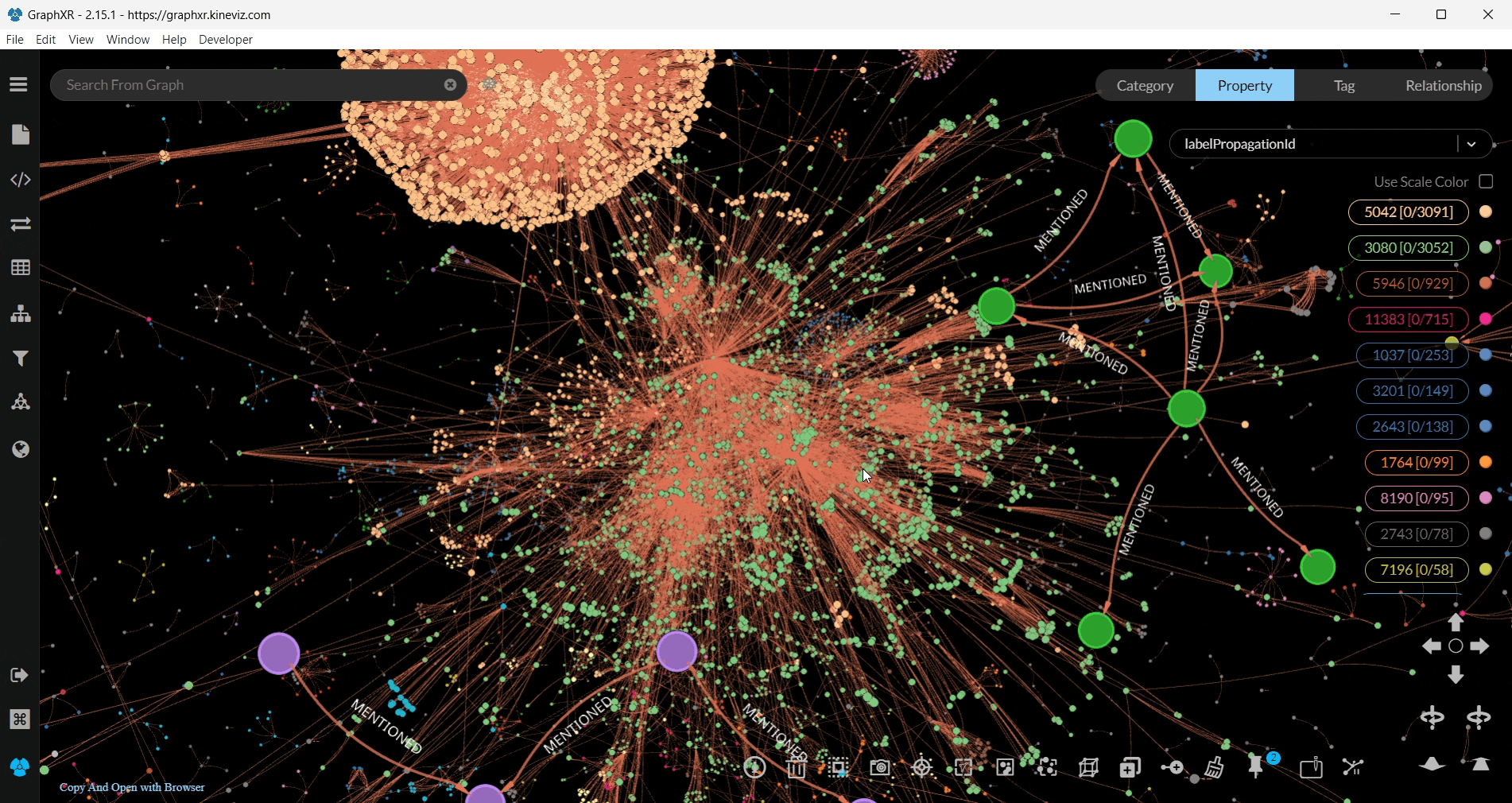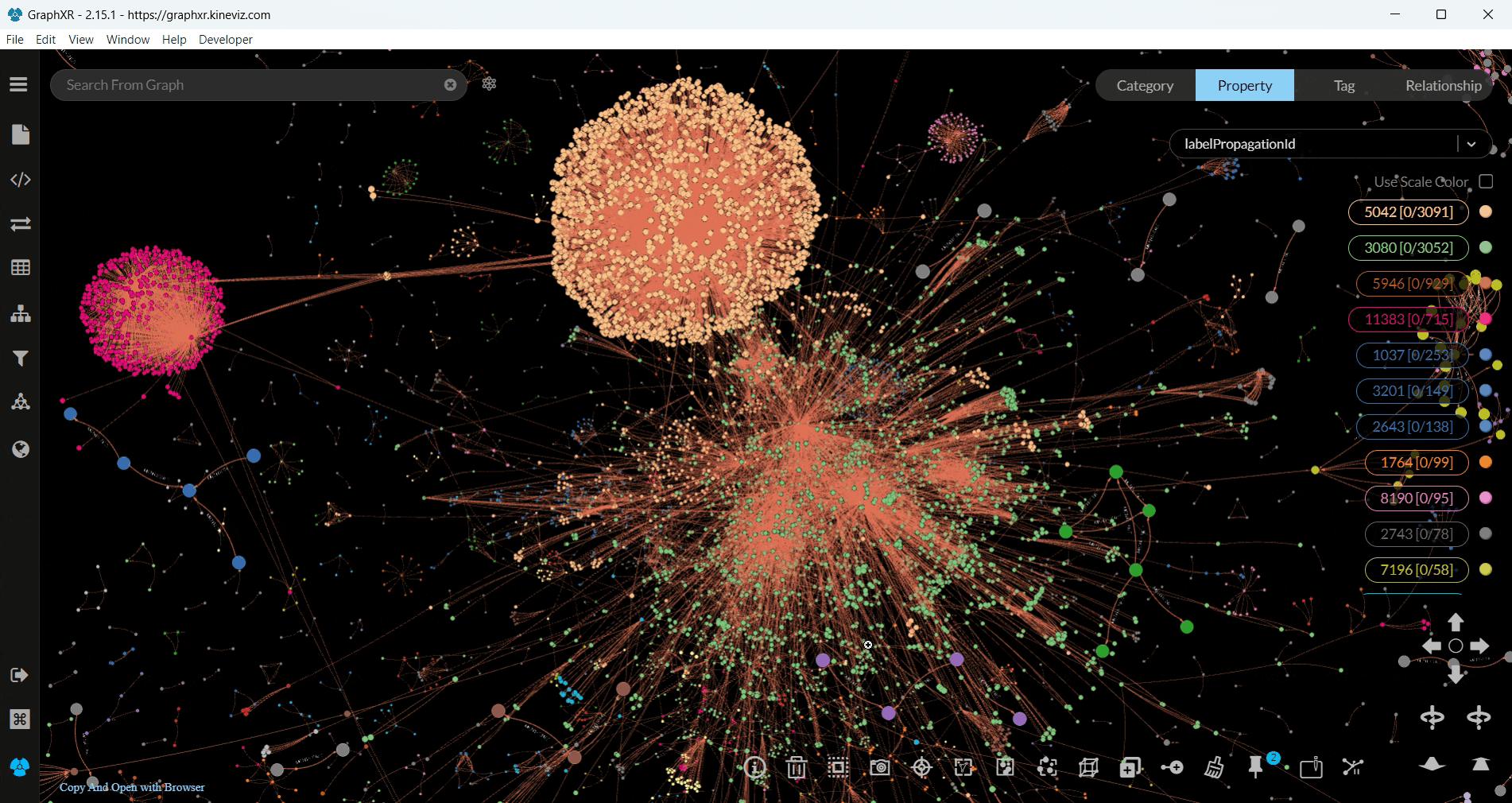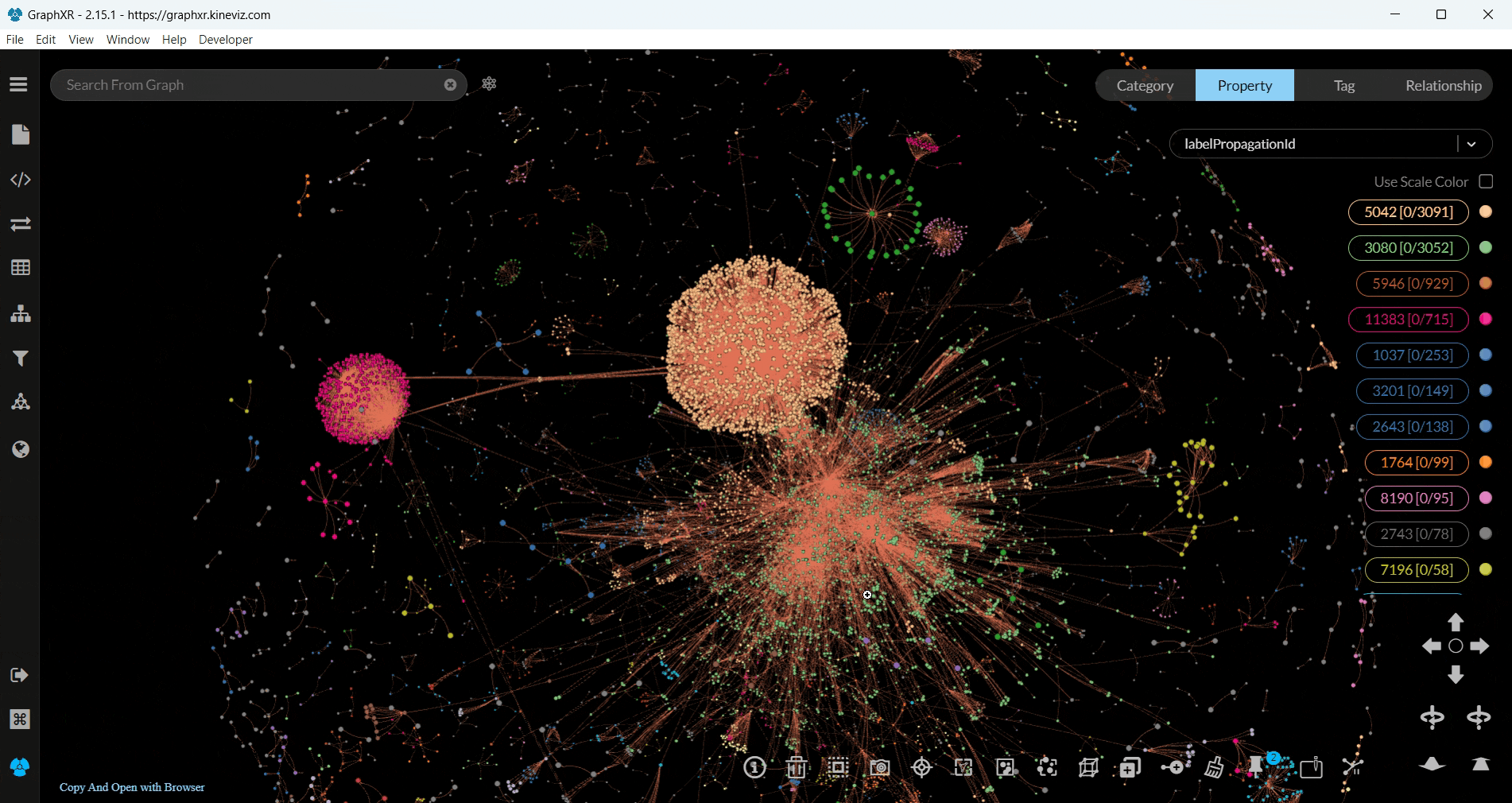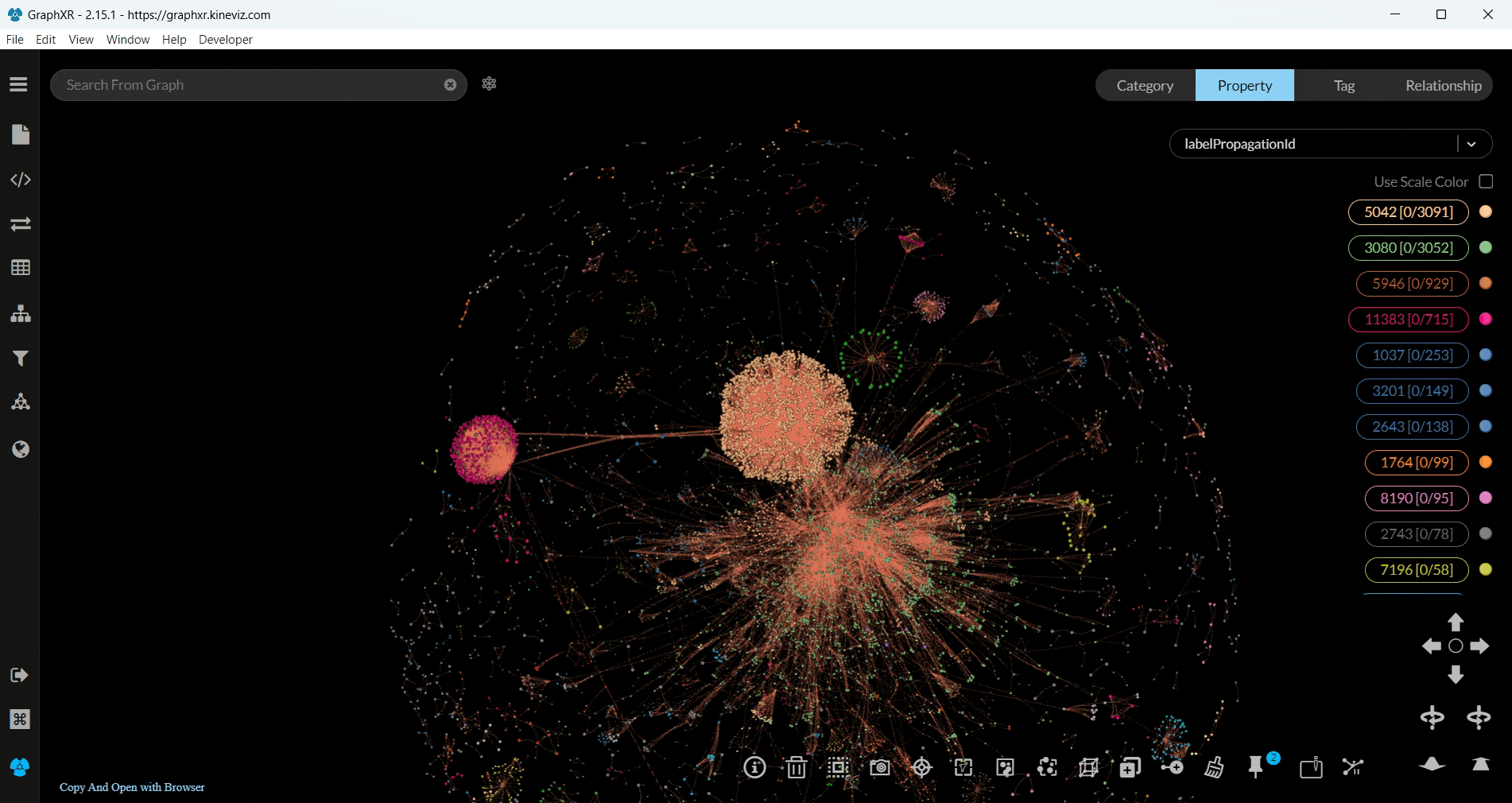
The visualisation was more interesting compared to the previous one we did with Louvain, since we got our results in 3D and the nodes within each community were presented with the same colour.
GraphXR contains numerous features you can explore, even creating your graph on the map, so if you are interested you should definitely give it a try!
You can always find the code for the complete project on Github.
Disclaimer: This article was written for the Web Data Mining class (SS 2023) in the MSc Program “Data and Web Science” at the Aristotle University of Thessaloniki. We express our gratitude to Professor Athena Vakali for her guidance and support. Special thanks to TAs Ilias Dimitriadis, Sofia Yfantidou, and Christina Karagianni for their assistance. We also acknowledge the Datalab laboratory at Aristotle University for providing resources and tools. Views expressed here are solely the authors’ and not necessarily those of the university or mentioned individuals. More information: https://datalab.csd.auth.gr/.
